

如果把储能比作一辆车,那充放电策略就是它的驾驶系统。回望过去几年,我们很多储能电站的策略,其实还停留在“新手村”:晚上10点充,上午10点放,雷打不动。这就像开车只盯着前方一条白线,不看路况、不看天气,更不看旁边的大货车。
但在电力现货市场波动剧烈的今天,这种“定速巡航”式的策略,往往经不起一次电价时段的调整,或者一次天气的突变。
真正有价值的策略,绝不是一辆只会踩固定油门的碰碰车,而是一辆能看路、会预判,甚至自己学会“什么时候该怂、什么时候能莽”的智能汽车。
这就是当前储能算法领域最务实的前沿方向——如何让一条单调的充放电曲线,学会思考,并且让强化学习来当它的策略大脑。
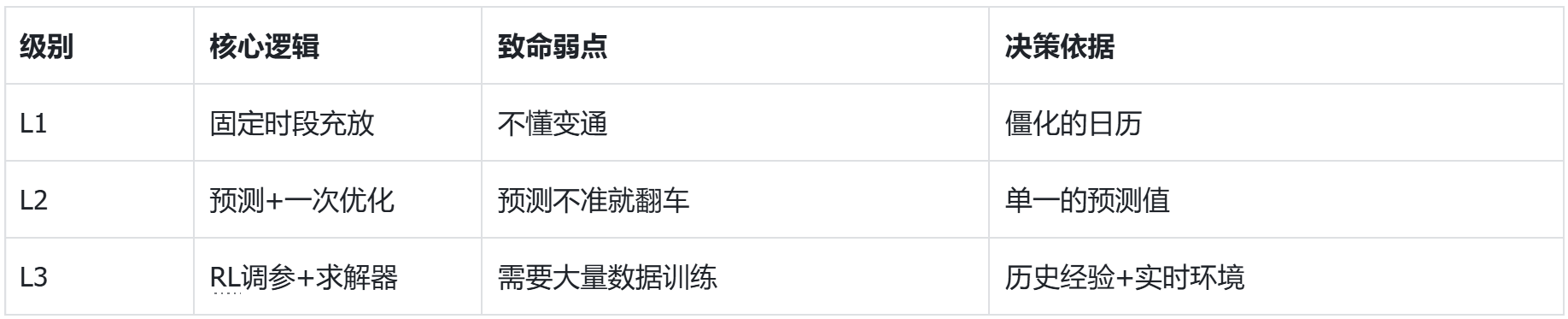
在储能圈,策略的进化其实很像汽车的自动驾驶分级。我们不妨对照一下,你的储能电站现在处于哪个段位?
画风: “日出而作,日落而息”。严格卡着固定的分时电价时段充放,不管当天电价曲线怎么变,我都雷打不动。
痛点: 在分时电价固定的年代,这叫“躺平式套利”,还能勉强维持。可一旦现货市场开启,或者遇到节假日调价,这套策略立刻失效。就像你设定好120码跑高速,结果前面是个急弯,车毁人亡。
画风: 引入了“电价预测模型”。基于对第二天负荷、风光出力、线路检修的预测,计算出最优计划,并实时微调。好比车辆加装了雷达,能根据前车距离自动加减速。
痛点: 核心问题始终存在——预测永远不可能100%准确。电力市场的预测误差,代价是不对称的。一旦预测错了(比如预测是尖峰结果是平段),整个策略的收益可能断崖式下跌,甚至导致全天无电可卖。
画风: 这是目前最前沿的范式。它不直接输出功率指令,而是让RL扮演一个“策略大脑”:每天根据市场环境,自动调整优化器的三个关键旋钮——风险厌恶系数、电池寿命权重、安全底线。
优势: 本质是“AI学会了根据天气和路况调整驾驶模式”,而方向盘和刹车(物理约束)仍由最可靠的数学优化来执行。
这三个层级的差异整理成了下表:
在聊L3之前,我们必须先正视一个问题:预测误差的代价是完全不对称的。
这就好比预测下雨带了伞却没下:顶多是麻烦一点,拿着累赘;预测晴天没带伞却下暴雨:那叫灾难,全身湿透。在电力市场中,这种“暴雨”经常发生。
一个典型的惨痛场景:某天午后,L2策略根据预测的“傍晚尖峰电价”,在中午大量充电,下午满功率放电。结果,尖峰没来,电价平平。电池SOC(荷电状态)见底。到了真正的晚高峰,面对高电价却无电可卖,只能束手无策。一次误判,锁死了整晚的灵活性。
这就是强化学习调参的价值所在。AI从过去几百天的历史数据中,已经“吃一堑长一智”。它能识别出某类看似美好的电价曲线其实暗藏风险,于是自动调高风险厌恶系数,让当天的求解器主动留出30%的容量底线——哪怕牺牲一点期望收益,也要保住晚间的选择权。
很多老板一听“强化学习”就觉得高深莫测,好像要把底层的控制逻辑全推翻。其实完全不是。它的工作原理,更像是一个“懂行的操盘手” ——它并不取代传统的数学求解器,而是站在求解器“上游”,根据市场环境的冷热变化,动态调整求解器的运行参数。
当我们说“强化学习是策略大脑”时,其实是在回答一个核心问题:你凭什么相信它能做出更好的决策?
在电力现货市场里,电价预测本质上无法做到100%准确。那么问题就变成了:我们能不能不用“预测一个数字”,而是换一种思路——让AI在无数次模拟交易中,自己摸索出在每一个市场状态下应该如何决策?
这正是RL的核心思想。它将储能的每日决策抽象成一个“马尔可夫决策过程”:
状态(State)= 今天的市场特征——预测电价曲线、日期类型、近期波动水平……
动作(Action)= 调整三个关键参数——风险厌恶系数、电池寿命权重、安全底线SOC
奖励(Reward)= 第二天用实际电价算出的真实净收益
RL要解决的数学问题,可以用一个通俗的公式来理解:
策略函数 π:S → A
S = 所有可能的市场状态(预测电价曲线、日期类型、波动率水平……)
A = 所有可选的动作(风险厌恶系数调高还是调低、电池寿命权重大小、安全底线设多少)
这个函数要达成的目标是:对于任意市场状态 s ∈ S,选择动作 a = π(s) 后,让下面这个长期期望累积奖励最大化:R(π) = E[ γ⁰·r₀ + γ¹·r₁ + γ²·r₂ + γ³·r₃ + …… ]。
其中:
rₜ = 第 t 步获得的即时奖励(赚了给正分,亏了给负分)
γ = 折扣因子,取值在 0 到 1 之间(比如 0.95),代表“今天的1块钱比明天的1块钱更值钱”
很多人以为RL的训练过程是“给AI正确答案让它学”,其实恰恰相反——RL是在一个虚拟市场里反复试错、不断“挨打”、从亏损中学出来的。
打个比方:这就像一个初出茅庐的交易员,我们在模拟器里给他设置了成千上万个交易日的市场环境。某一天他看到预测电价曲线高高翘起,就大胆满仓杀入——结果那天电价塌了,巨亏一笔,对应地受到一个沉重的“惩罚”信号。下一次又看到类似的曲线时,AI就会在心里打鼓:“等等,上次我好像在这儿被坑过。”
这个“惩罚”在算法层面就是奖励函数(reward function)的设计:
赚了钱 → 正向奖励
亏了钱 → 负向惩罚
电池充放过于频繁造成寿命折损 → 额外扣分
电量过低导致晚间无电可卖 → 重罚
通过数万次甚至数十万次这样的博弈,RL网络内部的权重被不断更新,AI逐渐积累起一套“直觉”:什么样的市场信号是可靠的,什么样的信号看起来美好但其实暗藏杀机。相关案例中,有研究在智利公用事业级光储项目上进行了跨两年实际运行数据的实证测试,DRL策略的14天平均利润接近55,000美元,且展现出稳健、自适应的逆周期行为。
训练完成后,RL进入日常运行。它和底层求解器形成了完美的配合,整个过程可以拆解为一个三步闭环:
AI不是算命先生,它需要“喂”数据。它接收次日的市场天气预报、96点预测电价曲线、日期类型(工作日/节假日)、市场近期的波动率水平。这些信息组合成一个“状态向量”,输入给强化学习策略网络。
策略网络经过离线训练,根据当前状态决定当天的“驾驶模式”。它不直接算功率,而是给出三个关键指令:
风险厌恶系数:今天预测置信度一般?加大风险惩罚,别太激进。
电池寿命权重:电池用了两年了,循环次数偏多?提高寿命保护,别把电池跑废了。
安全底线(Safety SOC) :今天是周五,周末市场波动大?强制要求傍晚前SOC不低于30%。
这三个参数进入底层的线性规划求解器。优化器在满足所有物理约束、互斥约束、爬坡约束的前提下,计算出最大化“收益-风险惩罚-寿命折损”的充放电策略。
关键点在于:所有电网安全底线,一行都不会破。
这一思路在国际学术界已有广泛验证。代尔夫特理工大学2025年发表的研究提出了MIP-DRL框架——将深度强化学习与混合整数规划相结合,利用MIP求解器在在线执行阶段严格强制所有运行约束,同时保证了高质量调度决策的有效性。
如果你看完上面的内容,觉得RL的训练就是“喂数据—跑模拟—看结果”这个套路,那我想跟你分享一点更深的东西——RL训练过程中真正的挑战,不是算法本身,而是如何让AI学到“可以跨场景迁移的直觉”,而不是死记硬背某一段历史行情的模式。
这里有一个很容易被忽略但极为关键的问题:过拟合与迁移能力的博弈。 如果把AI放在200天历史行情上疯狂训练,它可能会把这200天的模式“背”下来,但换到第201天全新的市场环境中就傻眼。这在机器学习中叫“过拟合”,在现实世界中就意味着真金白银的损失。
针对这个问题,前沿研究探索了多种应对机制:
一种做法是在训练中引入随机噪声扰动电价信号,让AI“知道”电价不可能完全准确预测,学会顺势而为;另一种做法是输入扰动,故意向AI的观测输入中注入电价残差扰动,模拟各种预测偏差场景,引导AI学会更保守、更稳健的决策风格。
还有研究引入条件风险价值(CVaR,Conditional Value-at-Risk)来显式惩罚低概率但大损失的极端事件,从而在期望收益与尾部风险之间取得平衡。最新风电-储能联合竞价的研究表明,采用SAC-CVaR框架的策略在保持97.3%风险中性利润的同时,将CVaR@95%改善了42.4%,实现了盈利能力与风险控制的有效协调。
评价RL好坏的核心标准不是历史表现,而是换一组没见过的数据后是否依然有稳定的收益。 这恰恰是L2“预测依赖症”永远无法解决的短板——因为L2在陌生场景下往往会暴露致命的脆弱性。
市场状态
(预测电价、日期特征、市场近期的波动率)
↓
RL策略网络 → 输出三个参数
↓
传统求解器 → 计算出充放电计划
↓
第二天用实际电价算出真实收益,作为奖励信号反馈给RL网络
这套流程每天自动运行。AI的奖励就是第二天基于实际电价的真实净收益。经过成百上千天的自我博弈,AI逐渐学会了:什么时候该贪,什么时候该怂,什么时候宁可少赚也要保住资产寿命。
光说不练假把式。我们在湖南一个100MW/200MWh的储能场站上,用今年4月上半月的实际运行数据,对L2和RL两种策略做了回测对比。
场景还原:
某日预测有尖峰但实际平缓。L2策略信以为真,中午凶猛充电,下午全力放电,功率曲线如尖锐锯齿;而RL策略则选择了“浅充浅放”,全天功率变化较小,明显更克制。
综合统计结果:
L2平均日收益 15154.36元,最大单日亏损高达 29245.5元;
RL平均日收益 16606.11元,最大单日亏损只有 746.03元;
同时,电池平均放电深度也有所降低,全生命周期衰减速度减缓。
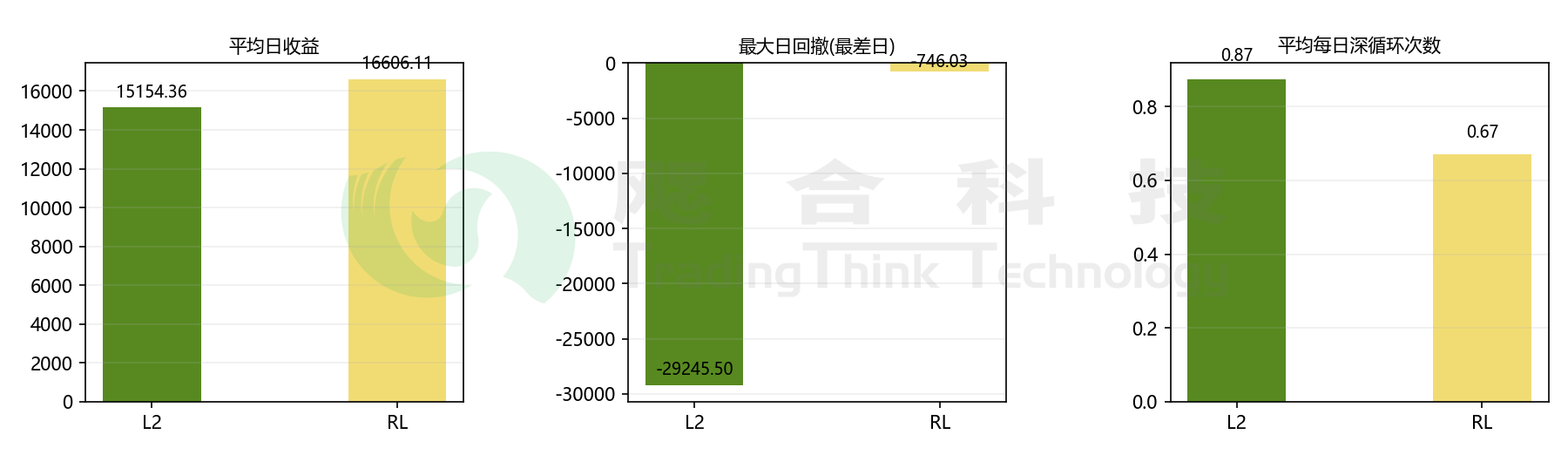
结论很扎心:
RL策略不仅收益更高,关键在于回撤极小。同时,电池的平均放电深度降低,全生命周期衰减速度减缓,这省下的可是真金白银的置换成本。
储能策略的进化,本质上是在不确定性的市场中寻找确定性。从L2的“预测-优化-执行”,到L3的“AI调参-求解器求解”,并没有替换掉数学优化的严谨性,反而是用强化学习给求解器装上了一双能观察风险的眼睛。
当策略学会了什么时候该保守、什么时候可以适当进取、什么时候必须给自己留一颗后悔药——这时候,储能电站才算真正睁开了眼睛,驶入了智能决策的赛道。


info@tradingthink.cn



